





So the first problem in this series is a straightforward one.
You are given a crawler that requests pages. But this crawler is very aggressive. Now, you do not want to burden the webserver too much. So you need to limit the crawler to at most one page per second while still doing it concurrently.
The solution
In this solution, you need to use a ticker from the time package. The time.NewTicker will return a channel that sends the time on every tick. You specified the period of ticks by the duration argument; the duration parameter is in nanoseconds. In this case, you need to pass the time. Second because you need to limit the crawl to one page per second.
For the limiter to actually work, you need to understand the behavior of an unbuffered channel. Once you know that, you have solved the problem.
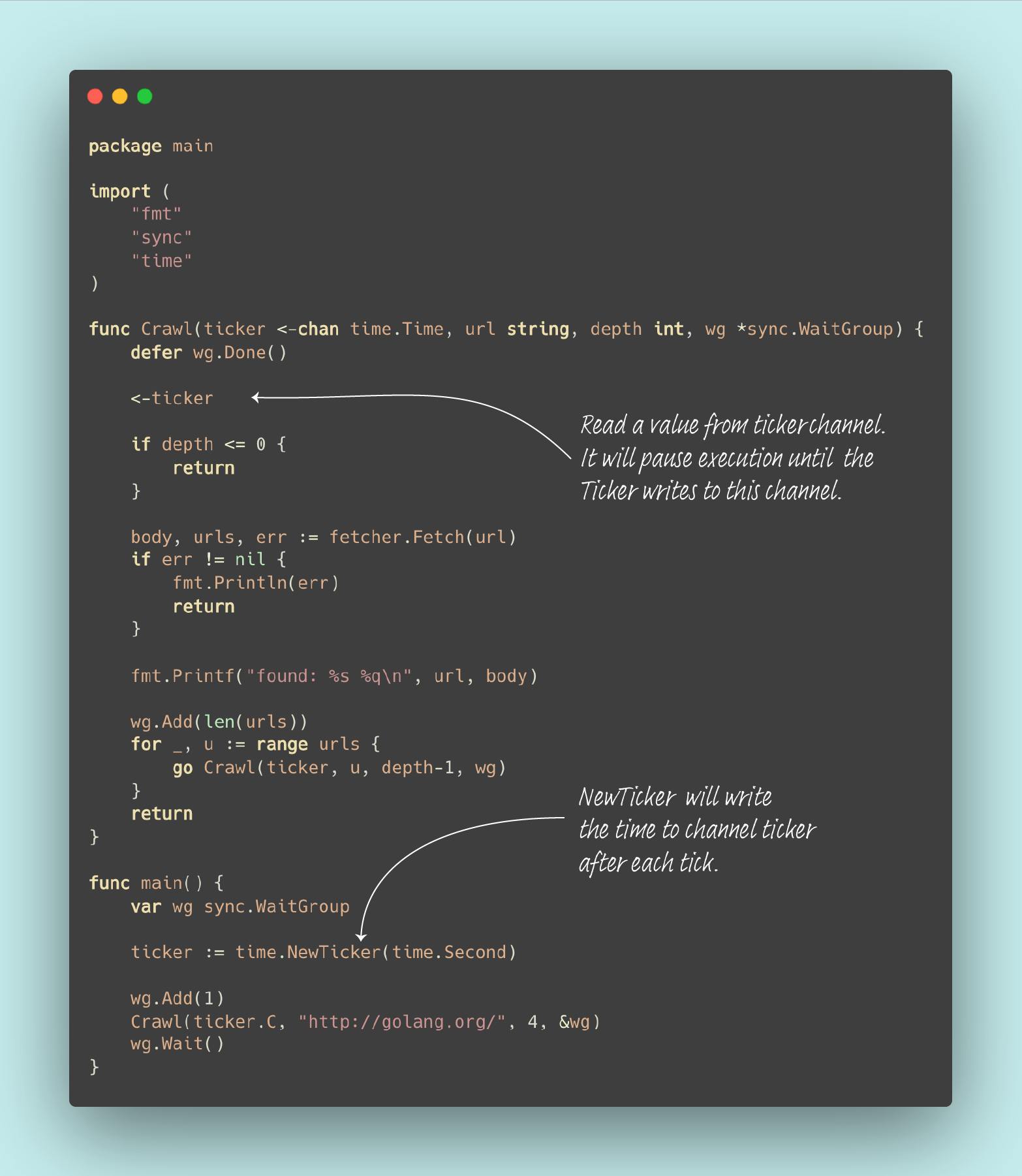
Key takeaway
Execution will pause when you read from an empty channel. If you read from an empty channel, in this case
ticker, the goroutine will pause. The execution will resume when the ticker writes to this channel on every tick (one second).Value written to a channel can only be read once. If multiple goroutines are reading from the same channel, a value written to the channel will only be read by one of them.
You need at least two concurrently running goroutines when you write to or read from an unbuffered channel.
Wrap up
This is a simple problem that shows how unbuffered channels behave. This is relatively straightforward, but it shows how execution pauses and resumes as you read from and write to a channel.